Neural networks
These pages are all about neural networks, an exciting way of programing computers to have machine intelligence.
What's a neural network?
Neural networks are a way of doing machine intelligence that is based roughly on how the brain works. The human brain has around 86,000,000,000 neurons, a type of cell, all connected in various ways with roughly 1.5x10^14 connections between them. Below you can see a diagram of a few connected neurons and what that would look like in an artificial neural network used in a computer.
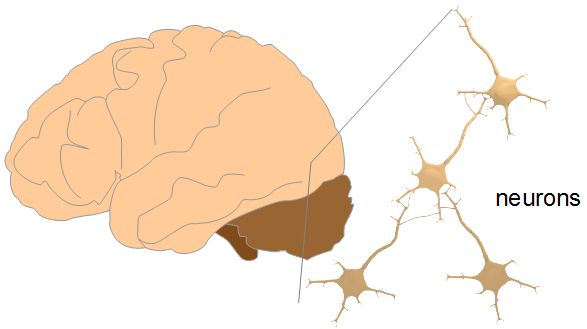
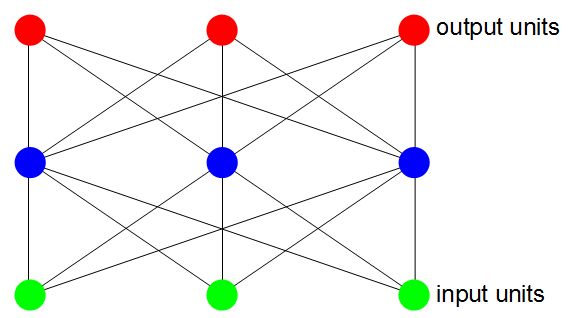
Looking at the neural network more closely, there are a set of input neurons and a set of output neurons. Instead of calling then neurons, we often call them units. In between the input units and output units are other units but just how many there are, how many layers of them and how they're configured depends on what you're using the neural network for. There are different types of neural networks for different tasks (image analysis, controlling robots, understanding sentences, producing sentences, ...)
To use it you first set the input units to whatever your input is, then you feed those inputs to whatever is in between and do a bunch of processing, and that produces the output on the output units.
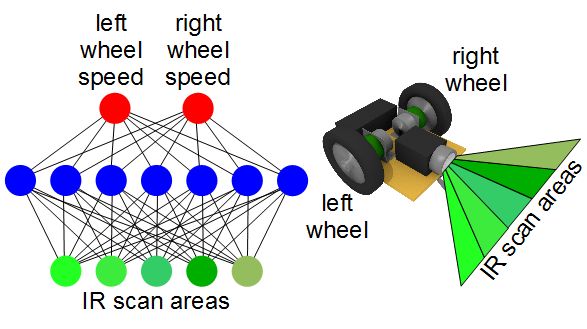
In the robot below, an infrared (IR) scanner on the front it scans for objects in front of the robot. The area scanned is broken up into 5 separate sections and the results from analysing these sections are the neural network's 5 inputs. The 2 outputs indicate how fast to rotate each wheel. Rotating one wheel faster than the other turns the robot.
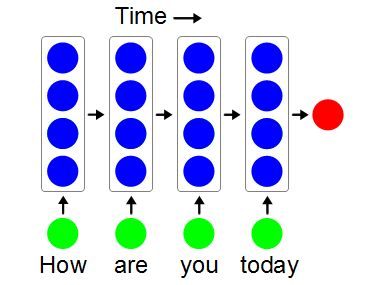
The example below is of a recurrent neural network (RNN). These types of networks are good for things that happen over a period of time, such as words of a sentence arriving one after the other. The diagram below is in time order. There is only one column of blue units and you're seeing it at four different times as each word arrives. When the sentence is finished, the output is some number representing that (hopefully) recognized sentence.
Deep neural networks (DNN)
Back in the 1970s to 1990s, neural networks were fairly shallow, having only a few layers in between the inputs and outputs. At the time is was difficult to train a neural network deeper than a few layers. But with improvements in computational speed, plus bigger data sets for training neural networks and improvements in algorithms, neural networks can now be many layers deep. Going deeper makes them in some cases better than humans at image recogition. It basically allows the networks to gain more sophisticated understanding of the input data.
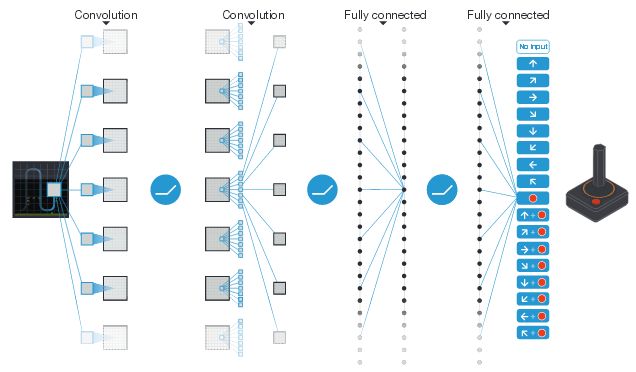
Here's an example of a neural network from a paper by Google DeepMind entitled "Human-level control through deep reinforcement learning" with multiple layers of different types. On the left it takes as input a screen capture of an Atari 2600 video game and the output is how the joystick should be moved.
Training the neural networks
The neural network needs to be taught to do whatever it's supposed to do. We call this training and there are many different ways of training the networks, sometimes depending on the type of network. Sometimes a combination of training methods are used.
The lines you see connecting the units in the diagrams usually have numbers associated with them, called weights. Training a network usually involves setting the values of these weights.
The best known training algorithm is backpropagation but there are many others. And even with backpropagation there are variations. The following is a video explaining how the backpropagation algorithm works.
Training deep neural networks
Deep neural networks are usually trained two layers at a time. For example, the input layer and the first hidden layer is taught, meaning that the weights between the two layers are adjusted over many training iterations. Then the first hidden layer is treated as an input layer and taught with the second hidden layer, and so on up to the last hidden layer and the output layer.
After all the layers have been taught this way, i.e. all the weights have been adjusted, then the deep network has a general knowledge of whatever it's been trained for. For example, if it was trained on images fed into the input layer, then combinations of various layers will have become specialized at picking out features. The first few layers will pick out edges, the next few layers will pick out shapes, and so on up the layers until the last few layers pick out types of objects (e.g. cats, cars, ..).
That neural network is now ready. In our example, its now a good image analyzing network for object recognition and can be more easily be trained for specific objects that was the purpose of training the neural network in the first place. Training now is done by presenting images of the objects at the input layer and telling it which output units should fire for those objects and this time, running the backpropagation alrogithm to train the entire deep neural network as a whole for each image.
Neural network APIs/libraries/frameworks
You can program your own neural network from scratch, but lately there have been more and more libraries and APIs made available online for you to use. All of the ones listed below run on normal computers as well as GPUs unless otherwise noted.
-
TensorFlow - Low-level machine learning API, including
for neural networks.
Languages: Python, C++ is on the way
Designed for distributing machine learning across multiple machines and GPUs. It's a low-level one, but a Keras (see below) version is being worked on specifically for TensorFlow. -
Keras - High-level neural network API.
Languages: Python
Uses other lower level frameworks such as TensorFlow and Theano underneath. Makes it easier to use TensorFlow and Theano. Plans are underway to support CNTK as well. A separate version of Keras is being worked on specially for TensorFlow. -
TensorFlow.js - Javascript neural network API.
Languages: JavaScript
JavaScript library for training and using neural networks. Uses WebGL acceleration. -
TFLearn - High-level neural networks API.
Language: Python
This is a high-level API that uses TensorFlow underneath, making it easier to use TensorFlow. -
MXNet - High-level neural networks API.
Languages: C++, Python, R, Scala, Julia, Perl, Matlab and Javascript
Runs on multiple platforms. -
PyTorch - High-level neural network API.
Language: Python
This is fairly new and runs on Linux and OS-X, using Torch underneath. -
Microsoft Cognitive Toolkit (CNTK) - Low-level neural network API.
Languages: Python, C++
Currently runs on Windows and Linux. A version is being worked on for Keras. - Apple's CoreML - Framework for integrating machine learning into apps that run on Apple products.
-
deeplearning.js - Machine learning APIs.
Lanugages: Javascript
This one can run in a browser. It has two APIs: an immediate execution API like NumPy, and a defferred execution API that mirrors TensorFlow. -
ConvNetJS - Neural network API.
Lanugages: Javascript (no GPU support)
This one can run in a browser. -
FANN (Fast Artificial Neural Network) - High-level neural
network API.
Languages: supports over 15 languages (no GPU support)
This has been privately developed for many years and is very popular, including being included in Linux distributions. It is limited to fully connected and sparsely connected neural networks i.e. no convolutional or recurrent neural networks. - Wekinator - Software to create mappings of gestures, sounds,... to actions to perform.
-
Caffe - High-level neural network API and command line interface.
Languages: command line tools, Python, MATLAB
This has been developed over many years by the Berkeley AI Research and community contributors. You can define the neural network in a plain text file, detail how to train it in a second plain text file called a solver, and then process it using the caffe command line tool for the training. You can then use the trained neural network within a Python program, for example. -
OpenAI Gym - Toolkit for developing and comparing reinforcement
learning algorithms.
Language: Python (more on the way) -
Torch - Neural network API.
Language: LuaJIT
-
Deeplearning4j - Deep learning for Java and Scala.
Languages: Java, Scala -
Theano - Numerical computation library.
Language: Python
This is an open source numerical computation library designed for efficiently processing multi-dimensional arrays, which are what neural networks mainly consist of. It runs on Windows, Linux and OS-X and has been developed by the University of Montreal since 1991.
When using Python neural network frameworks, you may come across mention of NumPy. NumPy is a scientific computation library for Python that makes possible fast computations which would otherwise be slower due to Python's being an interpreted language. CuPy is another such library.
The above are examples of libraries that can result in very powerful neural networks. If you want something simple and small to play with the there's my own simple 3 layer backpropagation neural network library.
You can even get some already trained neural networks such as the Caffe Model Zoo.
Machine learning online services
You can also do a lot of things using neural networks without having to program the neural network side of it. This is done using various online services.
-
Google Cloud Machine Learning (includes the following, plus more)
- Google Cloud Vision - Online service for vision applications.
- Google Cloud Speech - Online service for speech applicaitons.
- Microsoft Cognitive Services - Online services for vision, speech, language, ...
- Amazon's Alexa Voice Service
